Generally the voice mail systems separate the recording procedure and the play-back procedure. In the human-to-human conversation, however, we can barge in on the other. This manner of conversation can be simulated using the audio input and output simultaneously. Some speech dialog systems have the capability of the nodding with speech output and graphical display, which aim to show the internal status of the speech recognizer and the dialog manager[1].
The full duplex voice I/O also makes the human-to-human voice messaging system more attractive. From this point of view, we designed a system called AVM. It can play-back and record voice message simultaneously, while the other systems separate these processes (Figure 1).
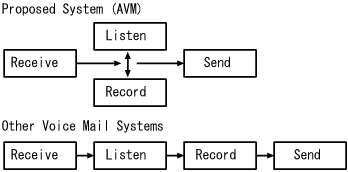
Figure: The method for recording messages in proposed system
compared to the other voice mail systems.
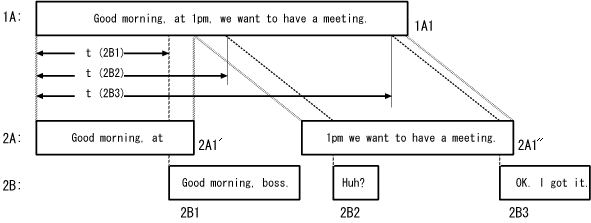
This system utilizes both the voice itself and the temporal information which the voice was spoken. An example of playing and recording messages in AVM is shown in Figure 2. At first, the utterance of speaker A is recorded as 1A1. In the second session requested by B, 1A is play-backed as 2A. Speaker B speaks three parts of utterances in reply to A. Each part of speech is separated by the certain length of silences and labeled as `interrupting' or `overlapping.' 1B1 is an interrupting part, and 1B2 and 1B3 are overlapping parts in this case. In the second session, therefore, the utterance 2A was paused by 2B1 and divided into 2A1' and 2A1''. The message 2B, which consists of 2B1, 2B2 and 2B3, is stored to the server after the second session.
In our goal, whether a part is interrupting part or not would be recognized in real time. At this moment, however, all parts of speech are regarded as `interrupting' or `overlapping' according to the application's option menu.
Figure: An example of playing and recording messages in AVM.
Each part of speech has the relative time to it's parent part.
In Figure 2,
the parent part of 2B1 is 1A1, and the relative time to the parent is
shown as 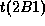 .
In case of 2B2 and 2B3,
the parent is also 1A1,
and the relative time is shown as
.
In case of 2B2 and 2B3,
the parent is also 1A1,
and the relative time is shown as 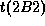 and
and 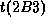 respectively.
respectively.
In AVM, the time scale in each meeting space changes dynamically.
When the user selects a set of messages, the message management server
decides the layout of the messages, then it generates
the sound and its markup data on demand.
The relative time of a part and its parent
is used in this procedure.
Other attributes are also used,
such as the `interrupting' or `overlapping' label,
and the words contained in the message itself
(transcribed manually or by using speech recognition).
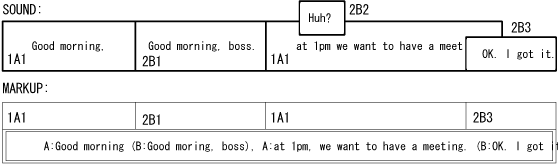
In Figure 3, there are four segments
which correspond to
the former part of 1A1, 2B2, the latter part of 1A1,
and 2B3, respectively.
The first and the third segments
are not equal to 2A1' and 2A1'',
because the message server found the more preferable point to divide 2A,
which may be the nearest word-boundary of 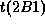 .
.
The dynamic conversation composing is one of the most important features of the system. Several functions such as speech recognition, automatic dialog tagging, language processing including modality conversion, and speech synthesis must be used to generate natural conversations.
Figure: An example of merged message by the AVM server.